Posts Tagged statistics
Supreme Court overturns tyranny of statistical significance
In today’s Wall Street Journal, The Numbers Guy (Carl Bialik) reports on a unanimous ruling by the Supreme Court that companies cannot hide behind statistical significance (lack thereof in this case) as an excuse for nondisclosure of adverse research. He passes along this practical advice:
“A bigger effect produced in a study with a big margin of error is more impressive than a smaller effect that was measured more precisely.”
— Stephen Ziliak, economics professor
However, this legal analysis of the ruling cautions that statistical significance remains relevant for assessing materiality of an adverse event.
Given all this, we can be certain of only one thing – more lawsuits.
Fun graphs and charts on names: How popular is yours and where is it populated?
My latest issue of National Geographic came with this fascinating mapping of population by surname. Seeing “Anderson” looming large over Minnesota did not surprise me, but I didn’t realize how many of us “snow birds” had permanently escaped to California. Take a look and see if you can locate any of you long-lost wander-kin around the USA.
The Junk Charts blog, one of my favorites, gave a generally favorable review of the “Nat-Geo” name chart, but they recommended an even-better one – the Baby Name Wizard, which plots the popularity of first names over the last 130 years.
I am expecting my first grandchild this summer, so there’s been lots of talks about names lately, thus this statistical chart caught my eye. You, too, may find it interesting. I suggest you start by hovering mouse over the widest streams (blue for boy, pink for girl) at the left (John, Mary, etc)* and then see how their popularity changes over the past 130 years. A tip: Click the graph to see trends for any given name, or enter it directly. Press “x” to get out of any specific name field (or type in another). I typed in my name and saw an explosion of popularity in mid-20th century, but now it’s fading away. The same holds true for my sister Nancy and my wife Karen – we all get tagged as baby-boomers straight away.
If you think there’s any chance of your name ranking in the top 1,000 for popularity in the USA at any time since 1880, type it in. How do you do, _______ (<= name here)?
Yankees leverage wins by throwing money at their players
Posted by mark in sports, Uncategorized on September 26, 2010
Today’s New York Times sports section provided this intriguing graphic on “putting a price tag on winning”. Their hometown Yankees stand out as the big spenders by far. It paid off in wins over the last decade – the period studied. However, if you cover up the point depicting the Yanks, the graph becomes far less compelling that salary buys wins – mainly due to counteractive results enjoyed by two low-payroll teams: The Minnesota Twins and the Oakland Athletics.
{kind=link}
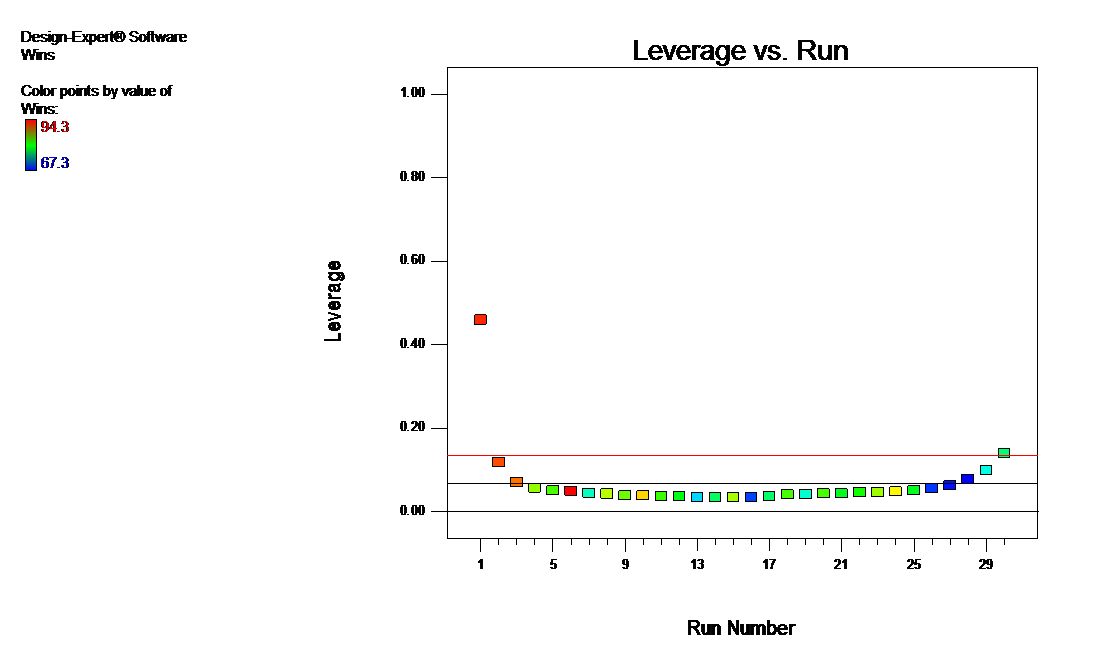
I found similar patterns and, more importantly, data to reproduce these, in this study of MLB Payroll Efficiency, 2006-2008 by Baseball Analyst Rich Lederer. No offense to Rich or the NY Times – it is the damn Yankees (sorry but I am weary of them defeating the Twins every post-season) who are the blame for this flaw in drawing conclusions from this data: One point exerts undue leverage on the fit, which you can see on this diagnostic graph generated by Design-Expert® software.
No offense to Rich or the NY Times – it is the damn Yankees (sorry but I am weary of them defeating the Twins every post-season) who are the blame for this flaw in drawing conclusions from this data: One point exerts undue leverage on the fit, which you can see on this diagnostic graph generated by Design-Expert® software.
However, after doing the obvious thing – yanking the Yanks from the data, the conclusion remains the same: Higher payroll translates to more wins in Major League baseball. Here are the stats with/without the Yankees:
- R-squared: 0.41/0.34
- Wins per $ million of payroll (slope of linear fit): +0.13/0.16
In this case, a high leverage point does not exert the potential influence, that is, the end result does not change due to its location. If you’d like to simulate how leverage impacts fit, download this educational simulation posted by Hans Lohninger, Associate Professor of Chemometrics at Vienna University of Technology.
What value for p is right for testing t (or tasting tea)?
Posted by mark in Basic stats & math, history on July 25, 2010
Seeking sponsors for his educational website, statistician Keith Bower sent me a sample of his work – this 5 minute podcast on p-values. I enjoyed the story Keith tells of how Sir Ronald Fisher, who more-or-less invented design of experiments, settled on the p value of 5% as being a benchmark for statistical significance.
This sent me scurrying over to my office bookshelf for The Lady Tasting Tea – a delightful collection of stories* compiled by David Salsburg.** Page 100 of this book reports Fisher saying that below p of 0.01 one can declare an effect (that is – significance), above 0.2 not (that is – insignificant), and in-between it might be smart to do another experiment.
So it seems that Fisher did some flip-flopping on the issue of what value of p is needed to declare statistical significance.
PS. One thing that bothers me in any discussion of p-values is that it is mainly in the context of estimating the risk in a test of the null hypothesis and almost invariably overlooks the vital issue of power. For example, see this YouTube video on Understanding the p-value. It’s quite entertaining and helpful so far as it goes, but the decision to accept the null at p > 0.2 is based on a very small sample size. Perhaps the potential problem (underweight candy bars), which one could scope out by calculating the appropriate statistical interval (confidence, prediction or tolerance), merits further experimentation to increase the power. What do you think?
*In the title story, originally told by Sir Ronald Fisher, a Lady claims to have the ability to tell which went into her cup first—the tea or the milk. Fisher devised a test whereupon the Lady is presented eight cups in random order, four of which are made one way (tea first) and four the other (milk first). He calculates the odds of correct identification as 1 right way out of 70 possible selections, which falls below the standard 5% probability value generally accepted for statistical significance. Salsburg reveals on good authority (H. Fairfield Smith–a colleague of Fisher) that the Lady identified all eight cups correctly!
**Salsburg, who worked for some years as a statistician at a major pharmaceutical company offers this amusing anecdote from personal experience:
“When I first began to work in the drug industry…one…referred to…uncertainty [as] ‘error.’ One of the senior executives refused to send such a report to the U.S. Food and Drug Administration [FDA]. ‘How can we admit to having error in our data?’ he asked [and]…insisted I find some other way to describe it…I contacted H.F. Smith [who] suggested that I call the line ‘residual’…I mentioned this to other statisticians…and they began to use it…It seems that no one [in the FDA, at least]…will admit to having error.”
A breadth of fresh error
Posted by mark in politics, Uncategorized on June 20, 2010
This weekend’s Wall Street Journal features a review by Stats.org editor Trevor Butterworth of a new book titled Wrong: Why Experts Keep Failing US – And How to know When Not to Trust Them. The book undermines scientists, as well as financial wizards, doctors and all others who feel they are almost always right and thus never in doubt. In fact, it turns out that these experts may be nearly as often wrong as they are right in their assertions. Butterworth prescribes as a remedy the tools of uncertainty that applied statisticians employ to good effect.
Unfortunately the people funding consultants and researchers do not want to hear any equivocation in stated results. However, it’s vital that experts convey the possible variability in their findings if we are to gain a true picture of what may, indeed, transpire.
“Error is to be expected and not something to be scorned or obscured.”
— Trevor Butterworth
Bonferroni of Bergamo
Posted by mark in Basic stats & math, history, Uncategorized on June 6, 2010

Bonferroni corrected

Uncorrected (random results)
I enjoyed a fine afternoon in the old Citta Alta of Bergamo in northern Italy – a city in the sky that the Venetians, at the height of their power as the “most serene republic,” walled off as their western-most outpost in the 17 century.
In statistical circles this town is most notable for being the birthplace of Carlo Emilio Bonferroni. You may have heard of the “Bonferroni Correction” – a method that addresses the problem of multiple comparisons.
For example, when I worked for General Mills the head of quality control in Minneapolis would mix up a barrel of flour and split it into 10 samples, carefully sealed in air-tight containers, for each of the mills to test in triplicate for moisture. At this time I had just learned how to do the t-test for comparing two means. Fortunately for the various QC supervisors, no one asked me to analyze the results, because I would have simply taken the highest moisture value and compared it to the lowest one. Given that there are 45 possible pair-wise comparisons (10*9/2), this biased selection (high versus low) is likely to produce a result that tests significant at the 0.05 level (1 out of 20).
This is a sadistical statistical scheme for a Machiavellian manager because of the intimidating false positives (Type I error). In the simulation pictured, using the random number generator in Design-Expert® software (based on a nominal value of 100), you can see how, with the significance threshold set at 0.05 for the least-significant-difference (LSD) bars (derived from t-testing), the supervisors of Mills 4 and 7 appear to be definitely discrepant. (Click on the graphic to expand the view.) Shame on them! Chances are that the next month’s inter-laboratory collaborative testing would cause others to be blamed for random variation.
In the second graph I used a 0.005 significance level – 1/10th as much per the Bonferroni Correction. That produces a more sensible picture — all the LSD bars overlap, so no one can be fingered for being out of line.
By the way, the overall F-test on this data set produces a p value of 0.63 – not significant.
Since Bonferroni’s death a half-century ago in 1960, much more sophisticated procedures have been developed to correct for multiple comparisons. Nevertheless, by any measure of comparative value, Bergamo can consider this native son as one of those who significantly stood above most others in terms of his contributions to the world.
Misuse of statistics calls into question the credibility of science
Posted by mark in science, Uncategorized on March 28, 2010
The current issue of Science News features an indictment of statistics by writer Tom Siegfried. He pulls no punches with statements like this:
“…a mutant form of math has deflected science’s heart..”
“Science was seduced by statistics…”
“…widespread misuse of statistical methods makes science more like a crapshoot.”
“It’s science’s dirtiest secret: …testing hypotheses by statistical analysis stands on a flimsy foundation.”
“Even when performed correctly, statistical tests are widely misunderstood and frequently misinterpreted. As a result, countless conclusions in the scientific literature are erroneous…”
Draw your own conclusions on whether science fails to face the shortcomings of statistics by reading Siegried’s article Odds Are, It’s Wrong.
My take on all this is that the misleading results boil down to several primary mistakes:
- Confusing correlation with causation
- Extrapolating from the region of experimentation to unstudied areas
- Touting statistically significant results that have no practical importance
- Reporting insignificant results from studies that lack power to see differences that could be very important as a practical matter.
I do not think statistics itself should be blamed. A poor workman blames his tools.
Gambling with the devil
Posted by mark in Basic stats & math, design of experiments on November 15, 2009
In today’s “AskMarilyn” column by Marilyn vos Savant for Parade magazine she addresses a question about the game of Scrabble: Is it fair at the outset for one player to pick all seven letter-tiles rather than awaiting his turn to take one at a time? The fellow’s mother doesn’t like this. She claims that he might grab the valuable “X” before others have the chance. Follow the link for Marilyn’s answer to this issue of random (or not) sampling.
This week I did my day on DOE (design of experiments) for a biannual workshop on Lean Six Sigma sponsored by Ohio State University’s Fisher College of Business (blended with training by www.MoreSteam.com.) Early on I present a case study* on a training experiment done by a software publisher. The goal is to increase the productivity of programmers by sending them to workshop. The manager asks for volunteers from his staff of 30. Half agree to go. Upon their return from the class his annual performance rating, done subjectively on a ten-point scale, reveals a statistically significant increase due to the training. I ask you (the same as I ask my lean six sigma students): Is this fair?
“Designing an experiment is like gambling with the devil: only a random strategy can defeat all his betting systems.”
— RA Fisher
PS. I put my class to the test of whether they really “get” how to design and analyze a two-level factorial experiment by asking them to develop a long-flying and accurate paper helicopter. They use Design-Ease software, which lays out a randomized plan. However, the student tasked with dropping the ‘copters of one of the teams just grabbed all eight of their designs and jumped up the chair. I asked her if she planned to drop them all at once, or what. She told me that only one at a time would be flown – selected by intuition as the trials progressed. What an interesting sampling strategy!
PPS. Check out this paper “hella copter” developed for another statistics class (not mine).
*(Source: “Design of Experiments, A Powerful Analytical Tool” by Christopher Nachtsheim and Bradley Jones, Six Sigma Forum Magazine, August 2003.)
Regions with aging populations are experiencing higher death rates!
Posted by mark in politics, Uncategorized on August 10, 2009
If the USA moves to government-sponsored health care on the scale of Europe, death rates here (now 8.3 per thousand) are sure to increase to the trans-Atlantic level of 10.3 — that’s a fear which Economist Edward Lotterman rebuts in his newspaper column today. As you educated readers might guess, the discrepancy in death rates can be easily explained by differing demographics: Due differing post-WWII dynamics, Europe’s population is older than ours, which can be seen in these animated population pyramids on Europe versus the United States developed by Professor Gerhard K. Heilig.
Specific statistics like this, when used indiscriminately by strongly-biased people, give statistics as a whole a bad name. However, those who are not duly diligent in vetting inflammatory stats are just as much to blame as the originators misleading them.
“It is proven that the celebration of birthdays is healthy. Statistics show that those people who celebrate the most birthdays become the oldest.” — Widely quoted as stemming from a PhD thesis by S. den Hartog (perhaps too good to be true!)
Overreacting to patterns generated at random – Part 2
Professor Gary Oehlert provided this heads-up as a postscript on this topic:
“You might want to look at Diaconsis, Persi, and Fredrick Moesteller, 1989, “Methods for Studying Coincidences” in the Journal of the American Statistical Association, 84:853-61. If you don’t already know, Persi was a professional magician for years before he went back to school (he ran away from the circus to go to school). He is now at Stanford, but he was at Harvard for several years before that.”
I found an interesting writeup on Percy Diaconis and a bedazzling photo of him at Wikipedia. The article by him and Moesteller notes that “Coincidences abound in everyday life. They delight, confound, and amaze us. They are disturbing and annoying. Coincidences can point to new discoveries. They can alter the course of our lives; where we work and at what, whom we live with, and other basic features of daily existence often seem to rest on coincidence.”
However, they conclude that “Once we set aside coincidences having apparent causes, four principles account for large numbers of remaining coincidences: hidden cause; psychology, including memory and perception; multiplicity of endpoints, including the counting of “close” or nearly alike events as if they were identical; and the law of truly large numbers, which says that when enormous numbers of events and people and their interactions cumulate over time, almost any outrageous event is bound to occur. These sources account for much of the force of synchronicity.”
I agree with this skeptical point of view as evidenced by my writing in the May 2004 edition of the Stat-Ease “DOE FAQ Alert” on Littlewood’s Law of Miracles, which prompted Freeman Dyson to say “The paradoxical feature of the laws of probability is that they make unlikely events happen unexpectedly often.“